
デロイト トーマツ コンサルティングの執行役員であり、デロイト トーマツ グループのDeloitte AI Instituteやアジア太平洋地域の先端技術領域を率いる森正弥氏に、生成AIが日本の製造業に与えるインパクトについて聞く本連載。
続く下編では、生成AIの導入で考慮すべきリスクやその対策、日本の製造業にもたらす変化や可能性についてお聞きしました。

アジア太平洋地域 先端技術領域リーダー
グローバル エマージング・テクノロジー・カウンシル メンバー
外資系コンサルティング会社、グローバルインターネット企業を経て現職。
ECや金融における先端技術を活用した新規事業創出、大規模組織マネジメントに従事。世界各国の研究開発を指揮していた経験からDX立案・遂行、ビッグデータ、AI、IoT、5Gのビジネス活用に強みを持つ。CDO直下の1200人規模のDX組織構築・推進の実績を有する。
東北大学 特任教授。東京大学 協創プラットフォーム開発 顧問。日本ディープラーニング協会 顧問。過去に、情報処理学会アドバイザリーボード、経済産業省技術開発プロジェクト評価委員、CIO育成委員会委員等を歴任。
著書に『ウェブ大変化 パワーシフトの始まり』(近代セールス社)、『両極化時代のデジタル経営』(共著:ダイヤモンド社)、『パワー・オブ・トラスト 未来を拓く企業の条件』(共著:ダイヤモンド社)、『信頼できるAIへのアプローチ』(監訳:共立出版社)がある。
多様化するリスクにどのように対処するか
――生成AIを活用することで生まれるリスクや、対策の方法についてお聞かせください。
生成AI以前から、AIの活用には情報漏洩やプライバシー保護、透明性、外部依存性、正確性や公平性というリスクがあることが議論されていました。ChatGPTはフロントオフィスやバックオフィスを問わず、文書作成から顧客対応まで幅広い業務において適用が可能ですが、その汎用性の高さゆえにリスクも多様化しています。リスクをコントロールするためには、システムセキュリティの最適化、社員への研修、ガイドラインの作成、さらにはユースケースを特定し、使用をその範囲内に抑えるなどの対策が挙げられます。
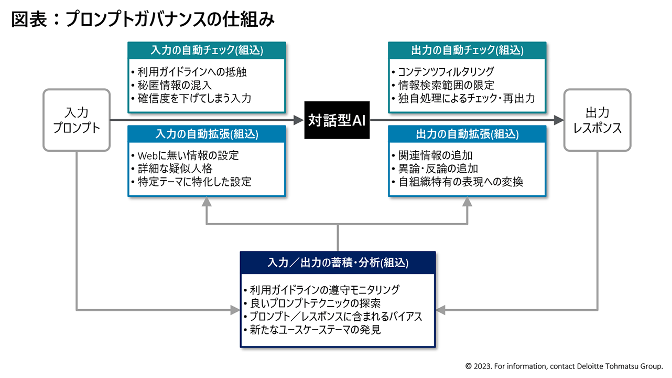
また、対話型生成AIはプラットフォーム側のアップデートによって振る舞いを変えることもあるため、再現性や同期性が維持されず、追跡可能性の確保が困難になるというリスクもあります。そこで私が提案しているのが、人間とAIの対話プロセスに連携した「プロンプトガバナンス」という仕組みです。
人間の入力とAIの出力の過程に「自動チェック」や「自動拡張」の機能を組み込み、対話を蓄積・分析することでガバナンス機能を改善・拡張していこうというものです。自動チェック機能は、入力の際にガイドラインに抵触しそうな内容や秘匿情報の入力を阻止し、出力の際にコンテンツのフィルタリング、検索範囲の限定、独自処理のチェックや再出力に対応します。また、自動拡張は、関連情報や異論・反論の追加、表現を自社特有のものに変換するといったことが可能です。蓄積されたプロンプトやガバナンスを分析し、ガイドラインの順守状況や良いプロンプトテクニックの発見、組織内のバイアスやコンプライアンス状況の把握などができるようになります。
さらに、生成AIの登場で新たに議論として持ち上がったのが、著作権の問題です。例えば、文書を著名な作家の作風に似せて書かせるといったようなものですね。そうした著作権侵害(画像生成AIであれば肖像権)に抵触しそうな活用を防ぐためには、アウトプットに関するポリシーを会社の中で規定する必要もあるでしょう。
――開発中のAIの学習に海賊版のデータが含まれていたことがわかり、サービス提供が先送りになったというニュースもありました。
そうですね、データの問題もあると思います。少し話が逸れますが、AIの学習に著作権を侵害するようなデータを使ってはいけないことはコンセンサスとして明らかですが、正しいデータだけを学習させればいいかといえば、実はそうではないのです。
――どういうことでしょうか?
我々がAIだと思っているものは、膨大なデータが特殊な形で結晶化されている、データの“おばけ”のようなものです。結晶の規模を表すものが、「パラメータ数」ですね。ChatGPT3.5なら1750億、4なら1兆を超えるといわれるものです。もっとも重要なのは、そのおばけのようなデータを適切に管理すること。AI開発はデータ管理であると言ってもいいでしょう。
世の中は成功もあれば失敗もあり、予期せぬミスが起こったが結果的には成功したなど、いろいろなことが起こります。AIも、そうしたすべての事象をとらえて判断を下さなければなりません。正しい情報だけでは現実から逸脱したものになってしまい、いいアウトプットを出すものにはならないということです。
2019年にアルファベットの子会社が発表した自動運転に関する論文に、腕のいいドライバーのデータを大量に学習させても良い結果が得られず、逆に運転が得意でない人のデータを学習させたところ性能が飛躍的に向上したというものがあります。
入れてはいけないデータはあるが、純粋化されたデータだけでは現実に対応できない。負のデータも学習させつつ、アウトプットを適切にするためのデータを選択することは、データマネジメントの難しい部分です。今はリスクコントロールやガバナンスが厳しくなっていますし、一部の人が人種や国籍、居住地域で不公平を被るようなデータ学習は避けるべきという難しさもあると思います。