
製造業では、IoT機器の普及により工場内で発生するデータ量が急増しており、これらのデータをいかに活用するかが競争力を左右する時代となりました。
センサーから収集される膨大な情報をリアルタイムに処理し、設備の異常検知や生産効率の改善につなげることが求められています。
しかし、従来のシステムでは大量データの即時処理や複数システム間の連携に課題があり、新たなデータ基盤の構築が必要です。
この記事では、製造業で注目されているApache Kafkaについて、活用される理由や具体的な導入事例、導入時の注意点などを詳しく解説します。
目次
Kafkaとは?
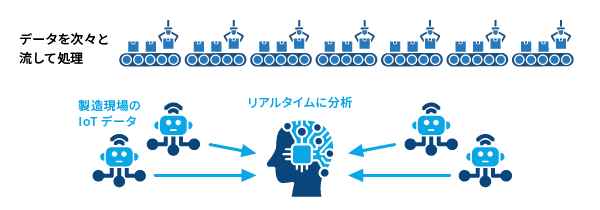
Apache Kafkaは、リアルタイムで大量のデータを処理できる分散型のメッセージングシステムです。元々はLinkedIn社で開発され、現在では多くの企業が採用しています。
工場のベルトコンベアのように、データを次々と流して処理する仕組みと考えるとわかりやすいでしょう。
製造現場のセンサーから収集されるIoTデータを、リアルタイムに分析して設備の異常検知や生産効率の改善に役立てる事例が増加しています。
Kafkaは高スループット、低レイテンシ、スケーラビリティを重視した設計となっており、秒間数百万件のメッセージの処理が可能です。
データの複製機構を持つため耐久性にも優れており、クラスター内の一部ノードが停止してもデータが失われにくい工夫がなされています。
MQTT、RabbitMQとの違い
MQTTは、IoTデバイス間の軽量な通信プロトコルとして広く使用されています。
RabbitMQは、メッセージキューイングに特化したシステムで、タスクの非同期処理に適しています。
Kafkaは、高スループットと分散処理に優れており、大量のデータを扱う用途に向いているでしょう。
製造業では、IoTデバイスからのデータ収集にはMQTTを使用し、そのデータをKafkaで処理するという組み合わせも採用されています。
用途に応じて適切なツールを選択し、必要に応じて組み合わせることが、効果的なデータ基盤構築のポイントです。
製造業でKafkaが活用される3つの理由
製造業においてKafkaが活用される理由は、主に以下の3点です。
- リアルタイムデータ処理の必要性
- 大量のIoTデータ管理
- システム間連携の複雑化
順番に解説していきます。
理由1:リアルタイムデータ処理の必要性
製造現場では、設備故障の予兆検知や品質異常の即座発見など、即時対応が求められる場面が増えています。従来のバッチ処理では、一定間隔によるデータ分析が一般的で、リアルタイムへの対応ができませんでした。
しかしKafkaを用いると、IoTデータをリアルタイムに処理でき、設備の異常を早期に検知したり、生産ラインのボトルネックを特定できます。
例えば、温度センサー、圧力センサー、振動センサーなどから収集されるデータをリアルタイムに監視することで、機械の故障を未然に防ぎ、ダウンタイムを削減できるでしょう。
リアルタイム可視化による迅速な意思決定が、生産効率の向上につながっています。
理由2:大量のIoTデータ管理
工場内の設備には、多様なセンサーが設置されており、設備の稼働状況を把握するための情報源となります。センサー・機器の増加によって、1日あたり数テラバイトのデータが発生するケースも珍しくありません。
Kafkaのスケーラビリティは非常に柔軟で、ノードを追加すればクラスター全体の処理能力を向上できます。
データ量の変動が激しいケースにも対応可能です。
工場内のセンサーを利用してリアルタイムに位置情報を収集し、1分間に数万メッセージ送信される情報を処理する活用事例もあります。
理由3:システム間連携の複雑化
製造業では、各部門が独自のシステムを使用していることが多く、データが分断・サイロ化している状況が見られます。ERP、MES、WMSといった既存システムとの統合が課題となっており、全社的なデータの統合や分析が困難です。
Kafkaは複数のデータソースを同時にサポートできるため、個別連携からハブ型連携への転換を実現します。疎結合アーキテクチャにより、新システム追加時の影響範囲を最小化できる点も大きなメリットでしょう。
システム負荷に対する時間的な余裕を作り、責任の切り分けを明確にすることが可能になります。
Kafka導入で得られる3つのビジネスメリット
Kafka導入によって得られるビジネスメリットは、以下の3点です。
- 生産効率の向上
- 品質管理の高度化
- コスト削減効果
順番に解説していきます。
メリット1:生産効率の向上
リアルタイム可視化により、経営者は迅速な意思決定を行えるようになります。データ量や処理性能に合わせたスケーラブルな拡張により、運用コストの適正化も実現できるでしょう。
多数のセンサーから発生するデータを適切に蓄積・活用することで、生産ラインの効率化が進みます。
データをリアルタイムで監視し、集計処理やデータ加工をバッチ処理で高速に実行し、BI/BAツールへ情報提供することも可能です。
メリット2:品質管理の高度化
製造プロセスのデータをリアルタイムに監視することで、品質のばらつきを抑え、不良品率を低減できます。
例えば、成形工程における圧力や温度などのデータを分析し、最適な製造条件を維持することで、品質を安定させることができるでしょう。
全数検査と予測的品質管理により、不良品流出を防ぐ仕組みが構築できます。トレーサビリティの強化も実現され、製品の製造履歴を詳細に追跡することが可能になります。
リアルタイム分析による異常検知と、データ分析での製造品質改善の両立が、企業の競争力向上につながっています。
メリット3:コスト削減効果
センサーデータから異常を検知し、機械の故障を未然に防ぐことで、ダウンタイムを削減できます。
予知保全の実現により、タイヤ製造装置の振動や温度などのデータをリアルタイムに監視し、異常なパターンを検知することで、故障の予兆を捉えた事例があります。
計画的な設備停止により、緊急対応によるコスト増を避けることができるでしょう。エネルギー消費の最適化も期待でき、データに基づく運転条件の改善によって電力使用量を削減できます。
データ活用基盤の構築により、AI/機械学習への発展性も備えており、将来投資としての価値も高いです。
製造業における具体的な活用事例
製造業におけるKafkaの活用事例として、以下の3つを紹介します。
- 自動車部品メーカーの設備保全
- 食品製造業のトレーサビリティ強化
- 電子部品工場のスマートファクトリー化
順番に解説していきます。
事例1:自動車部品メーカーの設備保全
ある自動車部品メーカーでは、連続的に発生し続けるデータを処理するミドルウェアとしてKafkaを自動車製造に役立てています。製造ラインの安定性を向上させることを目的とし、データストリーミング基盤を導入しました。
生産ラインの効率化や品質改善に役立てることで、設備の稼働率向上を実現しています。センサーから収集されるデータをリアルタイムで分析し、設備の異常検知を早期に行う体制を構築しました。
世界規模でデータストリーミングを活用することで、継続的なイノベーションにつなげています。
事例2:食品製造業のトレーサビリティ強化
食品製造業では、品質管理規制への対応が厳しく求められる業界特有の課題があります。
ある食品メーカーでは、製造プロセスのデータをリアルタイムに監視することで、品質のばらつきを抑える仕組みを導入しました。
コンプライアンス強化とコスト削減の両立を目指し、衛生管理記録の自動化を実現しています。センサーデータを活用して、温度管理や湿度管理を厳格に行うことで、製品の安全性を担保しました。
トレーサビリティの向上により、問題発生時の迅速な原因特定と対応が可能になっています。
事例3:電子部品工場のスマートファクトリー化
電子部品を製造する工場では、多品種少量生産への対応が課題となっています。リアルタイム生産計画調整を実現するため、装置内のセンサーや製造ラインから発生するデータの監視を行っています。
そこでデータ分析による製造品質の改善と、ストリーム処理でデータを準リアルタイムで監視する体制を構築しました。生産リードタイムの短縮により、顧客からの急な仕様変更にも柔軟に対応できるようになりました。
データドリブン型のものづくりを実現し、顧客満足度向上の副次効果も得られています。
Kafka導入時に確認すべき3つのポイント
Kafka導入を成功させるために確認すべきポイントは、以下の3点です。
- 既存システムとの統合計画
- 運用体制と技術スキル
- セキュリティとコンプライアンス
順番に解説していきます。
ポイント1:既存システムとの統合計画
製造業では、各部門が独自のシステムを使用しているため、データ統合が大きな課題となっています。
ERPやMESといった基幹システムとKafkaをどのように連携させるか、事前に詳細な計画を立てる必要があります。API連携やデータ連携方式の確認を行い、既存システムへの影響を最小限に抑える設計が重要です。
段階的移行計画を策定し、一度にすべてのシステムを切り替えるのではなく、段階的に導入することでリスクを軽減できます。データの標準化とガバナンスの確立も、全社的なデータ活用を進める上で欠かせない要素です。
ポイント2:運用体制と技術スキル
Kafkaの運用には、分散システムやストリーミング処理に関する専門知識が必要です。
必要な技術者スキルセットとしては、Javaやデータ処理に関する知識、そしてKafkaの設定やチューニングの経験が挙げられます。
自社に専門人材がいない場合は、外部パートナーの活用を検討することも有効な選択肢でしょう。トレーニング計画を立て、社内で運用できる体制を段階的に構築することが推奨されます。
開発者にとっての運用負担を下げ、本来の開発に集中できるよう、管理ツールの選定と導入も重要なポイントです。
ポイント3:セキュリティとコンプライアンス
Kafkaのセキュリティは「暗号化」「認証」「認可」の3つの柱を意図的に設定する必要があります。
データ暗号化については、TLS(Transport Layer Security)を使用して通信を暗号化することが推奨されます。
アクセス制御の設計では、SASL/SCRAMやmTLSといった認証メカニズムを使用し、セキュリティを構成します。
業界規制への対応として、ISO認証やISMS(情報セキュリティマネジメントシステム)への準拠も検討が必要です。
保存中と転送中の両方でデータを暗号化することで、メッセージの整合性を確保し、情報漏洩リスクを最小化できるでしょう。
Kafka導入の4ステップ
Kafka導入の基本的なステップは、以下の4つです。
- 現状分析と目的の明確化
- PoC(概念実証)の実施
- システム設計と構築
- 段階的展開と改善
順番に解説していきます。
ステップ1:現状分析と目的の明確化
まず、自社が抱える課題を洗い出し、Kafka導入で何を実現したいのかを明確にします。
製造現場のデータ活用における問題点を特定し、どの工程からデータを収集するのか、どのような分析を行うのかを整理しましょう。
KPI設定を行い、導入効果を測定する指標を決めることで、プロジェクトの成功基準が明確になります。
投資対効果の試算も重要で、初期投資とランニングコストを見積もり、どれくらいの期間で投資を回収できるかを検討します。経営層の理解と承認を得るためにも、具体的な数値目標とロードマップの提示が必要です。
ステップ2:PoC(概念実証)の実施
本格導入の前に、小規模環境での検証を行うことで、技術的実現性を確認します。
特定の製造ラインや設備に限定してKafkaを試験的に導入し、データ収集から分析までの一連の流れを検証しましょう。失敗しても損失が少ないアプローチを取ることで、リスクを最小限に抑えながら学習できます。
PoCの結果をもとに、システム要件や構成方針を見直し、本番環境の設計に反映させます。
技術的な課題や運用上の問題点を早期に発見し、対策を講じることが可能になります。
ステップ3:システム設計と構築
インフラ設計では、Kafkaが動作するためのハードウェア要件を満たす環境を準備します。
JDK(推奨:Java 11以降)のインストールと、十分なディスク性能とメモリ容量の確保が必要です。
データフロー設計では、どのシステムからどのシステムへデータを流すのか、データの形式や処理方法を詳細に決めます。
セキュリティ実装として、TLS暗号化や認証機能を設定し、データ保護の仕組みを構築しましょう。
Kafkaクラスタを構成する場合は、複数Brokerを運用するためのファイアウォール設定や、ネットワーク設計も欠かせません。
ステップ4:段階的展開と改善
パイロット運用を開始し、限定的な範囲でKafkaシステムを稼働させます。運用中に発生する問題を記録し、システムのチューニングや設定変更を行いながら、安定稼働を目指しましょう。
全社展開計画を策定し、パイロット運用で得られた知見を活かして、他の部門や工場への展開を進めます。継続的な最適化として、データ量の増加やユーザー数の増加に応じて、システムをスケールアウトしていきます。
運用ノウハウを蓄積し、社内でKafkaを活用できる人材を育成することで、長期的な成功につなげられるでしょう。
Kafkaの今後の展望
製造業におけるKafkaの活用は、今後さらに拡大していくと予想されます。
IoT市場の成長に伴い、製造現場で扱うデータ量は爆発的に増加しており、リアルタイムデータ処理の需要は高まり続けています。
AI・機械学習技術との統合が進むことで、Kafkaは単なるデータ連携基盤から、高度な分析を支える中核インフラへと進化するでしょう。
エッジコンピューティングとの連携により、工場内での分散処理がさらに進み、よりリアルタイム性の高いデータ活用が可能になります。
5G通信の普及により、遠隔地の工場間でのデータ共有や、グローバルでのデータ統合が容易になることも期待されます。
スマートファクトリーの実現に向けて、Kafkaはデータドリブン型ものづくりの基盤として、ますます重要な役割を担っていくことでしょう。
まとめ
Apache Kafkaは、リアルタイムで大量のデータを処理できる分散型メッセージングシステムで、秒間数百万件のメッセージ処理が可能です。
製造業では、IoTセンサーから収集されるデータをリアルタイムに分析し、設備の異常検知や生産効率改善に活用されています。
導入により得られるビジネスメリットは次の通りです。
- 生産効率の向上(リアルタイム可視化と迅速な意思決定)
- 品質管理の高度化(不良品率低減とトレーサビリティ強化)
- コスト削減効果(予知保全によるダウンタイム削減とエネルギー最適化)
今後はAI・機械学習技術との統合やエッジコンピューティングとの連携が進み、5G通信の普及により、スマートファクトリー実現の中核インフラとしての役割がますます重要になると予測されています。