
製造業のデジタル化が進む中、IoTセンサーや生産管理システムから日々大量のデータが生み出されています。
これらのデータを効率的に管理し、ビジネスの意思決定に活用することが競争力強化の鍵となっており、次世代のデータ管理基盤として「レイクハウス」が注目を集めているのです。
一方で、従来のデータウェアハウスやデータレイクとの違いや導入のポイントを正しく理解する必要があります。
この記事では、製造業におけるレイクハウスの定義や導入メリット、活用事例、注意すべきポイントなどを詳しく解説します。
目次
レイクハウスとは?
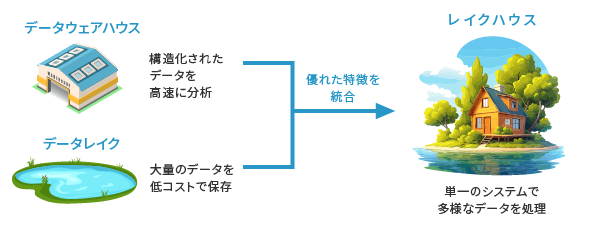
レイクハウスは、データレイクとデータウェアハウスの優れた特徴を組み合わせた、次世代のデータ管理基盤です。
従来、企業はデータレイクで大量のデータを低コストで保存し、データウェアハウスで構造化されたデータを高速に分析していました。
しかし、この2つのシステムを別々に運用すると、データの移行作業やシステム維持に多大なコストがかかる課題があったのです。
レイクハウスは、低コストなデータレイクを基盤として、その上にDelta Lakeなどの技術を活用することで、データウェアハウスの管理機能や信頼性を実装します。
これにより、単一のシステムで多様なデータを扱えるようになりました。構造化データ、非構造化データ、半構造化データのすべてを一元管理できるため、製造業における生産管理データやIoTセンサーデータを組み合わせた分析が容易になります。
製造業がレイクハウスを導入する3つのメリット
製造業がレイクハウスを導入することで得られる主なメリットは以下の3つです。
- メリット1:全社データの統合による迅速な意思決定
- メリット2:AI・機械学習による予知保全の実現
- メリット3:コスト削減とシステム運用の効率化
順番に解説していきます。
メリット1:全社データの統合による迅速な意思決定
レイクハウスを導入すると、部門ごとに分散していたデータを一つの基盤で管理可能です。データ分断が解消され、全てのデータが信頼できる形で一元化されるため、これまで見えなかったビジネスの洞察を得られます。
例えば、製造業では生産管理システムのデータと工場のIoTセンサーデータを組み合わせて分析することで、生産効率を低下させている真の原因を特定できます。
部門横断の分析が容易になることで、マーケティング部門が収集したデータと営業部門の顧客情報をシームレスに統合し、新たな事業機会を素早く見つけ出すことも可能です。
これにより、経営層はデータに基づいた迅速かつ的確な意思決定を行えるようになり、市場の変化に素早く対応できる体制を構築できます。
メリット2:AI・機械学習による予知保全の実現
レイクハウスは、AI・機械学習を活用した予知保全を実現する基盤として優れた性能を発揮します。
工場内のIoTセンサーから取得される大量の稼働データと、生産管理システムに蓄積された製品データを統合することで、特定のセンサーデータの異常が生産不良につながるパターンをAIが学習できます。
これにより、設備の故障を事前に予測し、最適なタイミングでメンテナンスを実施する仕組みを構築できるのです。製造業では、予期せぬ設備の停止が生産計画全体に大きな影響を与えるため、予知保全による計画的なメンテナンスは極めて重要です。
レイクハウスを活用することで、ダウンタイムを大幅に削減し、生産性を向上させることが可能になります。
メリット3:コスト削減とシステム運用の効率化
レイクハウスは、従来のデータレイクとデータウェアハウスを別々に運用する場合と比較して、システム運用コストを大幅に削減できます。
データレイクの低コストなストレージを基盤としているため、大量のデータを経済的に保管できる点も特徴です。
従来のアーキテクチャでは、データレイクからデータウェアハウスへデータを移行するETL処理が必要でしたが、レイクハウスではこの処理が不要になります。
これにより、データ移行作業の負担が減り、保守人員を最適化できるメリットがあります。
さらに、クラウドネイティブな設計により、ビジネスの成長に合わせて柔軟にスケーリングできるため、初期投資を抑えながら段階的にシステムを拡張していくことが可能です。
従来のデータ基盤との2つの決定的な違い
レイクハウスと従来のデータ基盤である「データウェアハウス」「データレイク」と比較してみましょう。
違い1:データウェアハウスとの比較
データウェアハウスは構造化されたデータを高速に分析できる一方、画像やテキストといった非構造化データの扱いが苦手です。また、データを保存する前にスキーマ(データ構造の設計)を決める必要があり、後からデータ構造を変更することが困難です。
コスト面では、データウェアハウスのストレージは高価なため、データの保持期間を短くせざるを得ない課題があります。
対してレイクハウスは、あらゆる種類のデータをそのままの形式で低コストに保存でき、必要に応じてデータ構造を柔軟に変更できます。
さらに、レイクハウスはデータウェアハウスと同等の高速なクエリパフォーマンスを実現しながら、非構造化データにも対応できる点が大きな違いです。
違い2:データレイクとの比較
データレイクは、構造化・非構造化を問わずあらゆるデータを低コストで大量に保存できる利点があります。
しかし、データの品質が管理されないまま蓄積されると、いわゆる「データスワンプ(データの沼)」と呼ばれる状態に陥り、活用が困難になるという課題も。
また、データレイクは信頼性が低く、BIツールとの連携がしにくいため、そのままではビジネス分析に活用しづらい特性があります。
レイクハウスは、データレイクの柔軟性を維持しながら、トランザクション管理やスキーマ定義の機能を持たせることで、データの品質と信頼性を確保します。
これにより、生データの柔軟な活用と、高速で信頼性の高い分析を両立させることが可能になりました。
製造業におけるレイクハウスの活用事例3選
ここからは、製造業におけるレイクハウスの活用事例を3つ紹介していきます。
順番に見ていきましょう。
事例1:自動車部品メーカーの予知保全による生産性向上
ある自動車部品メーカーでは、工場内に設置されたIoTセンサーから収集される振動、温度、圧力、稼働時間などの時系列データをレイクハウスにリアルタイムで取り込み、そのままの形式で保存しています。
この大量の未加工データに対してAI・機械学習を適用することで、機械の異常な挙動や故障の兆候を自動的に検知するモデルを構築しました。
従来は設備の故障が突然発生し、生産ラインが停止してしまうことが課題でしたが、レイクハウスの活用により実際に故障が発生する前にメンテナンスを行う「予知保全」を実現しました。
機器の微細な振動パターンの変化を機械学習モデルで分析することで、故障の兆候を早期に検知できるようになり、ダウンタイムを削減しています。
さらに、計画的なメンテナンスにより部品交換コストの最適化にも成功し、生産性を大幅に向上させることができました。
事例2:食品製造業の品質トレーサビリティ強化
食品製造業では、原材料の調達から製造、出荷に至るまでの全工程でデータを収集し、レイクハウスに統合しています。
工場のIoTセンサーデータと生産管理システムのデータを組み合わせることで、製品の品質検査データと製造プロセスデータを突き合わせる分析が可能になりました。
これにより、不良品発生の根本原因を特定し、歩留まりの改善や品質の安定化につなげています。
また、製造工程全体のデータが一元管理されているため、製品ロットごとのトレーサビリティが強化され、万が一問題が発生した際の原因追跡が迅速に行えるようになりました。
食品安全規制への対応においても、レイクハウスによる統合データ基盤は大きな役割を果たしており、クレーム対応時間の短縮にもつながっています。
事例3:精密機器メーカーのサプライチェーン最適化
精密機器メーカーでは、サプライチェーン全体のデータをレイクハウスに集約し、可視化を実現しました。部品調達から在庫管理、生産計画、出荷に至るまでの膨大なデータを統合することで、サプライチェーン全体の最適化に取り組んでいます。
レイクハウスを活用した分析により、在庫データと需要予測データを組み合わせて、欠品や過剰在庫を削減することに成功しました。
また、各工程のリードタイムを可視化することで、ボトルネックとなっている工程を特定し、改善策を講じることができました。こうした取り組みにより、運転資金の削減と納期短縮の両方を実現し、顧客満足度の向上にもつながっています。
レイクハウス導入前に確認すべき3つの注意点
レイクハウス導入前に確認すべき注意点は以下の3つです。
- 注意点1:自社のデータ成熟度の見極め
- 注意点2:ベンダーロックインのリスク管理
- 注意点3:人材育成と組織体制の整備
順番に解説していきます。
注意点1:自社のデータ成熟度の見極め
レイクハウスを導入する前に、自社のデータ成熟度を正しく評価することが重要です。
データガバナンス体制が整っていない状態で導入すると、データの品質が管理されないまま蓄積され、「データスワンプ(データの沼)」と呼ばれる状態に陥ってしまいます。
データガバナンスとは、組織が保有するデータ資産を適切に管理し、その価値を最大化するための方針やルール、プロセスなどの体系的な仕組みです。
データの定義を統一し、誰がどのデータにアクセスできるかを制御するアクセス管理、命名規則や分類方法などの標準化といった要素を事前に整備する必要があります。
自社のデータ管理が未成熟な場合は、段階的にデータガバナンス体制を構築しながら、レイクハウスの導入を進めることが成功への近道です。
注意点2:ベンダーロックインのリスク管理
特定のベンダーのシステムや技術に依存しすぎると、将来的に他社への切り替えが困難になる「ベンダーロックイン」のリスクがあります。
ベンダー固有の技術や手法で導入を進めてしまうと、自社内でシステム設計の内容を把握することが難しくなり、他社での改修も困難になります。
ベンダーロックインを回避するためには、オープンソース技術や標準規格に基づいたシステムを選ぶことが重要です。
例えば、Delta LakeやApache Iceberg、Apache Hudiといったオープンフォーマットを採用することで、幅広いベンダーでの改修が可能となり、特定のベンダーへの依存度を低く保てます。
また、契約時には「データのエクスポートが可能か」「解約時の移行支援を受けられるか」といった条件を明記し、将来的な乗り換えをスムーズに進められるよう備えておくことが大切です。
注意点3:人材育成と組織体制の整備
レイクハウスの運用には、従来のデータウェアハウスとは異なる技術スキルを持った人材が必要です。データレイクのインフラは、データウェアハウスとは異なるため、従来のデータエンジニアには通常このタスクに対する技術的な能力がない場合が多く、経験の浅い人材はさらに多くの時間と労力を必要とします。
組織には独自の経験・スキルをもつ人材が必要ですが、すぐには見つからないのが現実です。そのため、外部パートナーやコンサルタントの活用を検討しながら、並行して社内人材の育成計画を立てることが重要になります。
また、データ活用を成功させるためには、経営層のコミットメントが不可欠であり、全社的な取り組みとして推進する組織体制を整備する必要があります。
レイクハウス導入のための5ステップ
レイクハウス導入を成功させるための手順は以下の5ステップです。
- 現状分析とゴール設定
- PoC(概念実証)の実施
- アーキテクチャ設計と基盤構築
- データ移行と統合
- 本格運用と継続改善
順番に解説していきます。
ステップ1:現状分析とゴール設定
まず、自社が保有するデータ資産の棚卸しから始めます。
どの部門にどのようなデータがあり、どのように管理されているかを明確にすることで、データの全体像を把握できます。
次に、レイクハウス導入によって解決したい優先課題を特定しましょう。予知保全による設備停止時間の削減なのか、品質管理の高度化なのか、サプライチェーンの可視化なのか、目的を明確にすることが重要です。
そして、具体的な数値目標(KPI)を設定し、導入効果を測定できる状態を整えます。
ステップ2:PoC(概念実証)の実施
PoCは、「概念実証」や「実証実験」と呼ばれる検証手法で、本格的な開発や導入の前に試作品や簡易版で試すことで、リスクを抑えながら実現可能性や効果を確かめるものです。
小規模なデータセットを用いて、レイクハウスの有効性を検証します。製造業では高額な設備投資や長期的な開発期間が必要となるため、PoCによる事前検証が特に重要視されています。
実際の業務環境を想定した状況を再現し、データを収集・分析することで、よりリアルな効果測定が可能です。
PoCの結果をもとに、費用対効果(ROI)を試算し、本格導入の判断材料とします。
ステップ3:アーキテクチャ設計と基盤構築
PoCで効果が確認できたら、本格的なアーキテクチャの設計に移ります。
クラウド環境の選定では、AWS、Azure、Google Cloudなど、自社の要件に合ったプラットフォームを検討します。セキュリティ設計も重要な要素であり、データのアクセス制御や暗号化、コンプライアンス対応などを含めた設計が必要です。
また、データパイプラインを構築し、既存システムからレイクハウスへデータを自動的に取り込む仕組みを整えます。この段階で、オープンフォーマットの採用やマルチクラウド対応など、将来的な柔軟性を確保する設計を心がけることが重要です。
ステップ4:データ移行と統合
基盤構築が完了したら、段階的にデータ移行を進めます。
一度に全てのデータを移行するのではなく、優先度の高いデータから順次移行することで、リスクを最小限に抑えられるでしょう。既存システムとの連携を確保しながら、レイクハウスへのデータ統合を進めていきます。
データ移行後は、データ品質の検証を徹底的に行い、データの正確性、完全性、一貫性、最新性といった品質要素の確認が必要です。問題が発見された場合は、データクレンジングや修正を行い、信頼できるデータ基盤を構築します。
ステップ5:本格運用と継続改善
データ移行が完了したら、本格的な運用フェーズに入ります。
運用体制を確立し、データ管理の責任者やデータスチュワードを明確にすることで、持続的なデータガバナンスを実現します。ユーザートレーニングも重要で、データアナリストやビジネス部門の担当者がレイクハウスを効果的に活用できるよう教育しましょう。
運用開始後も、データ活用状況をモニタリングし、継続的な最適化を図ることが成功の鍵となります。
ユーザーからのフィードバックを収集し、システムの改善やデータ品質の向上に役立てることで、レイクハウスの価値を最大化していきます。
レイクハウスの今後の展望
レイクハウス市場は今後、飛躍的な成長が見込まれています。
世界のデータレイクハウス市場規模は、2033年には740億米ドルに達し、2025年から2033年までの年平均成長率(CAGR)は23.2%で成長すると予測されています。
特に製造業では、IoTデバイスの利用拡大により大量のデータが日々発生しており、それらを効率的に管理しながらリアルタイム分析を行う必要性が増しています。
さらに生成AIとの融合も注目されており、企業がもつ独自の情報を生成AIに効果的に教え、AIの回答の精度や関連性を大幅に向上させる取り組みが進んでいます。
今後、レイクハウスは単なるデータ基盤からAI活用基盤へと進化していくことが予想され、製造業のデジタルトランスフォーメーションを加速させる中核的な役割を担うでしょう。
まとめ
レイクハウスは、データレイクとデータウェアハウスの利点を統合した次世代データ管理基盤であり、低コストで多様なデータを一元管理しながら高速分析を実現します。
製造業では、部門横断のデータ統合による迅速な意思決定、AI・機械学習を活用した予知保全、システム運用コストの削減という3つの主要メリットが得られます。
| 項目 | 内容 |
|---|---|
| 主なメリット | データ統合による意思決定の迅速化、AI予知保全、コスト削減 |
| 活用事例 | 自動車部品:故障予測、食品:品質管理、精密機器:在庫最適化 |
| 導入注意点 | データガバナンス整備、オープンフォーマット採用、人材育成 |
導入時はデータガバナンス体制の整備とオープンフォーマット採用によるベンダーロックイン回避が重要であり、世界市場は急速に拡大し生成AIとの融合によりAI活用基盤へと進化しています。